岡崎研究室は、自然言語処理、すなわち言葉を操るコンピュータの研究を中心に、人工知能の実現を目指しています。
例えば、外国語の文章を翻訳する、相手と対話する、質問に答える、状況を説明する、といった知的なコミュニケーションをコンピュータ上で実現するための原理や方法を探求しています。
言語学、統計学、機械学習などの基礎を踏まえながら、深層学習や大規模言語モデルなどの最先端のアプローチも積極的に取り入れています。
さらに、ビッグデータ解析による社会観測など、研究成果の実社会での応用も展開しています。
研究内容
自然言語理解
コンピュータが人間の言葉を操れるようになるには、文章を「読む」能力が欠かせません。自然言語理解は、コンピュータが文章を解析し、5W1Hのように意味の構造を取り出したり、知識や意味、感情、意見などを取り出す研究です。岡崎研究室では、固有表現認識や関係抽出、語義曖昧性解消、感情分析などのタスクに取り組みながら、コンピュータがテキストデータを自動的に分析する研究を進めています。
自然言語生成
自然言語生成では、コンピュータが文章を「書く」能力に関して研究を行います。岡崎研究室では、機械翻訳や自動要約、文法誤り訂正、広告文生成などのタスクに取り組んでいます。大規模言語モデルの登場により、コンピュータは驚くほど流暢な文章を生成できるようになりましたが、生成される文章の長さやスタイル、伝え方などを適切に制御する研究に取り組んでいます。
マルチモーダル処理
自然言語処理では言葉に関する知能を扱っていますが、人間の知能は視覚や聴覚、身体性(物理的な身体があること)の影響を大きく受けています。「りんご」や「赤い」といった単語の意味や、「リンゴが木から落ちる」といった文章の意味を考えるとき、物理世界との対応付けをコンピュータが認識できる必要があります。岡崎研究室では、主に画像と言語を対応付けた機械翻訳や説明文生成などのタスクに取り組みながら、マルチモーダル処理の研究を進めています。
研究成果の例
国際会議の発表論文リストや国内口頭発表のリストも併せてご覧ください。
Swallowコーパスの構築
オープンな日本語LLMの学習にはCC-100、mC4、OSCARなどのコーパスの日本語部分が用いられてきました。ところが、これらのコーパスは日本語テキストの品質を重視して作られた訳ではありません。本研究ではCommon Crawlのアーカイブ(2020年から2023年にかけて収集された21スナップショット分、約634億ページ)から日本語のテキストを独自に抽出・精錬し、約3,121億文字(約1.73億ページ)からなる日本語ウェブコーパスを構築しました。
(岡崎 直観 et al., 2024)
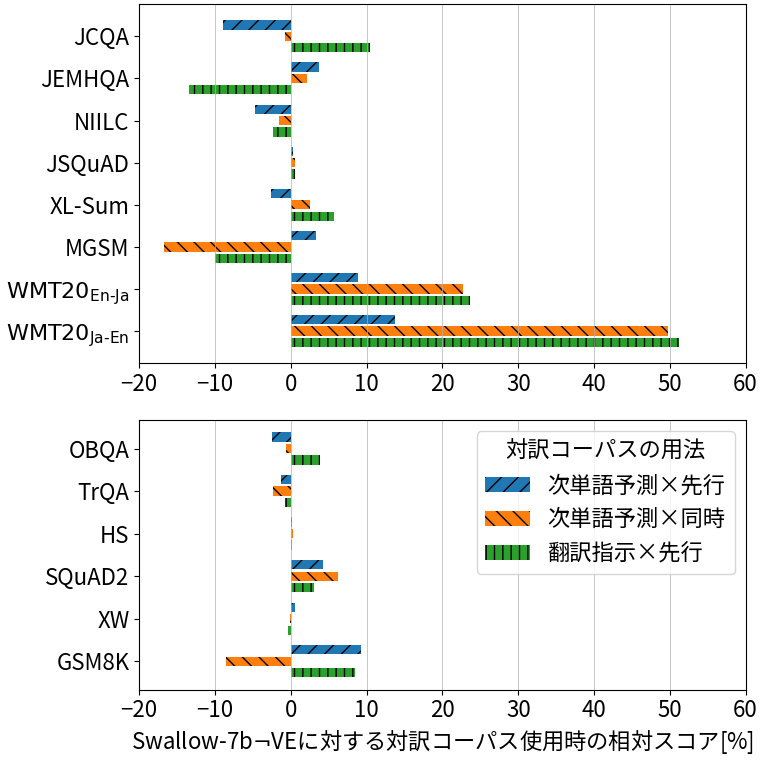
LLMの継続事前学習
英語の訓練データで学習したLLMに後から日本語の訓練を行う継続事前学習は,高性能な日本語LLMを構築する有望なアプローチの一つです。本研究では、継続事前学習の効果を分析し、特に日本語の質問応答で効果的であることを明らかにしました。また、LLMの能力を効率的に強化する方法として、日本語の語彙および対訳コーパスの有効性を調査しました。その結果、語彙拡張による効率化は要約を除き性能への悪影響はないこと、対訳コーパスの併用が翻訳能力を強化することを明らかにしました。
(水木 栄 et al., 2024)
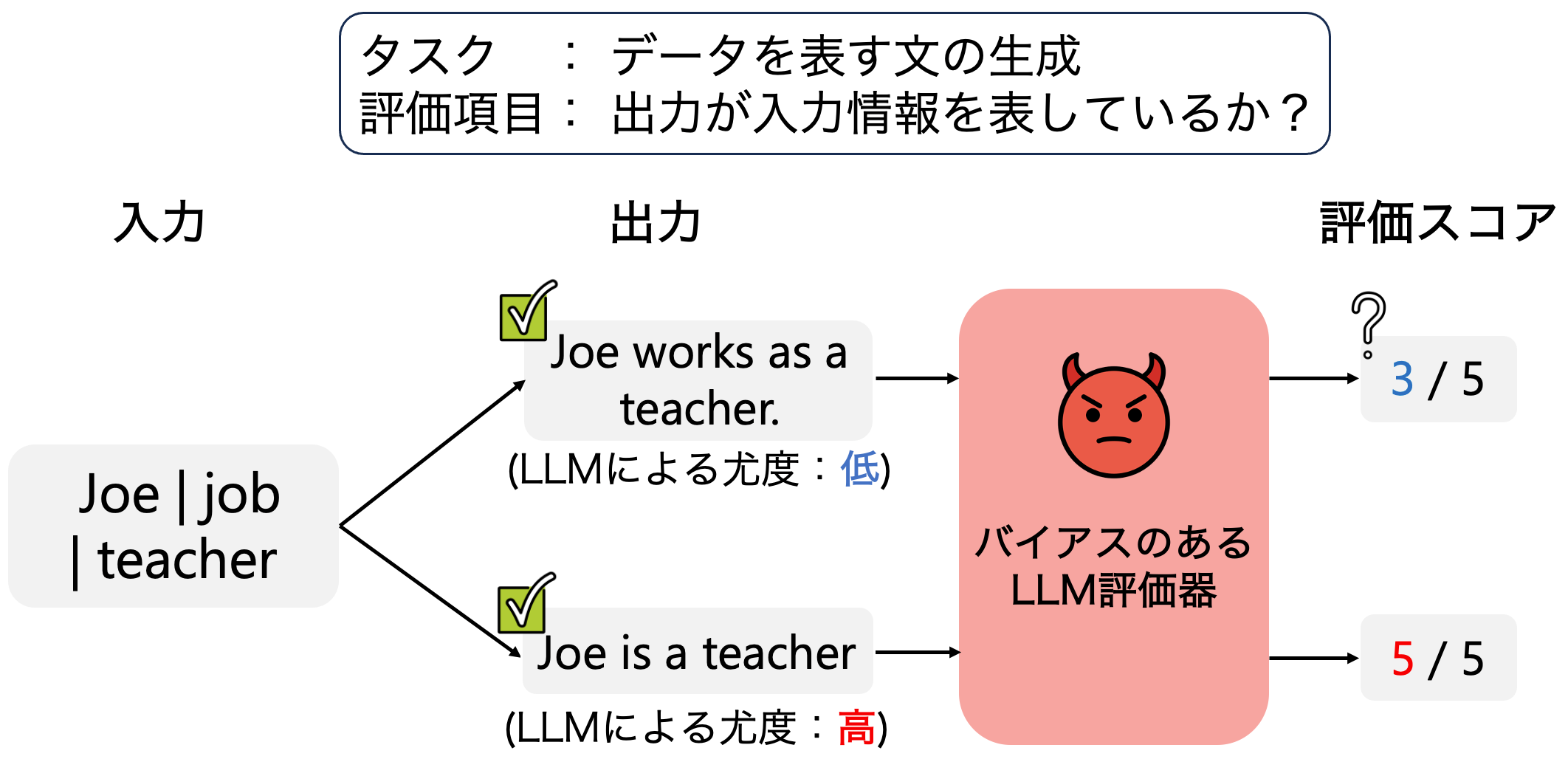
LLMの評価バイアスの緩和
LLMは自然言語生成の自動評価器としても用いられています。ところが、LLM評価器は尤度が低い文章を不当に低く、尤度が高い文章を不当に高く評価する尤度バイアスが存在します。本研究では、尤度バイアスがLLM評価器の性能を低下させることを明らかにし、Few-shotによるバイアス緩和手法を提案しました。
(大井 聖也 et al., 2024)
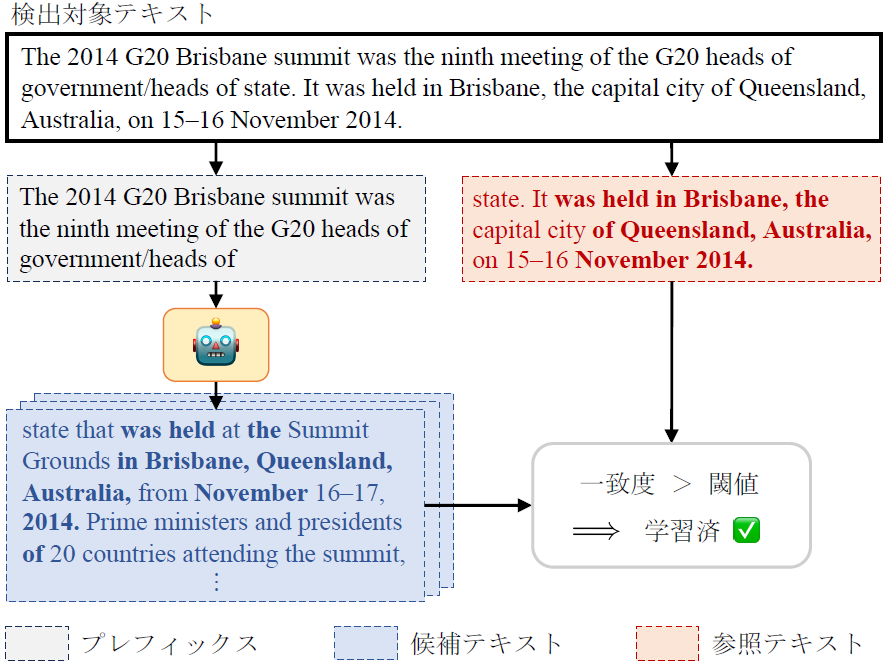
LLMへのメンバーシップ推論攻撃
与えられたテキストがLLMの学習データに含まれていたかを判定するメンバーシップ推論攻撃は、LLMが生成する文章が著作権違反を引き起こし得るのか、検証できます。従来手法は、モデルが計算する尤度を利用するため、適用できるモデルが限らていました。本研究では、LLMの出力テキストのサンプリングに基づき、検出対象のテキストの一致度を推定するサンプリングベース・メンバーシップ推論攻撃を提案しました。
(綿 祐貴 et al., 2024)
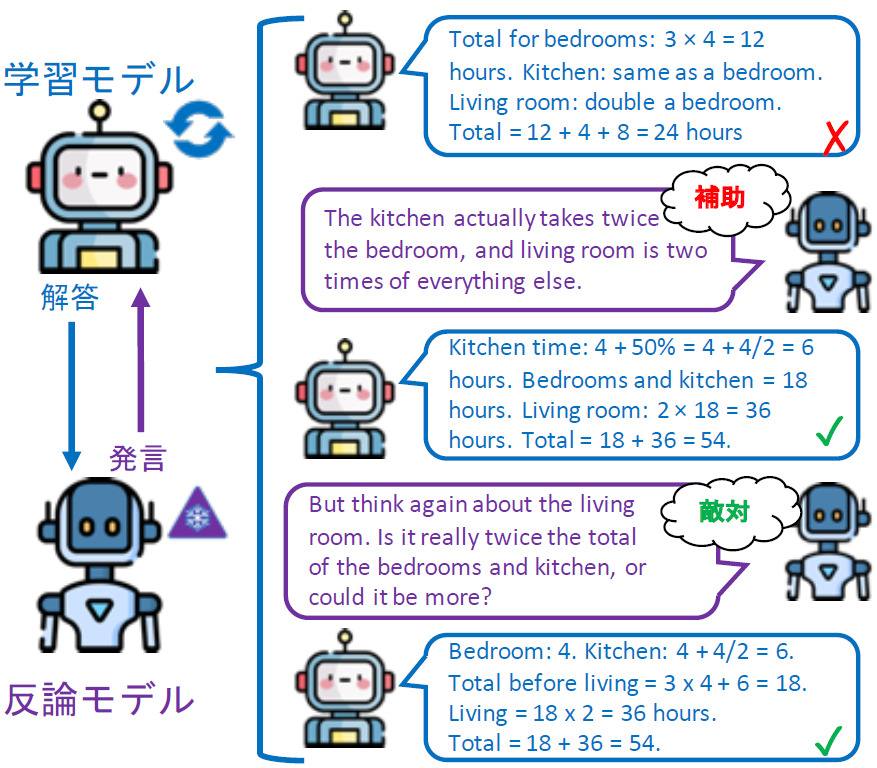
補助的・敵対的な議論によるLLMの強化
LLMは他のLLMや人間との議論を通じて、論理的・批判的思考力や説明力を高められると考えられます。従来研究では、学習モデルが正解に近づくように、推論時に議論を活用していました。本研究では、学習モデルの出力が不正解の場合には正解に近づくように(補助的)、出力が正解の場合には不正解に誘導するように(敵対的)議論を行い、学習モデルのファインチューニングを行う方法を提案しました。
(Loem et al., 2024)
分散表現における文字情報
LLMは入力テキストに含まれる単語や文字を数えたり、部分文字列を認識したり、回文を作成したりといった、テキストの表層的な情報を必要とするタスクを苦手としています。本研究では、事前学習済みのサブワード・単語の分散表現が表層的な知識(文字数や部分文字列)を獲得しているか検証し、分散表現が文字数や部分文字列の情報をある程度捉えているものの、どの文字が何番目に出現するかといった順序の情報は獲得できていないことを明らかにしました。
(平岡 達也 et al., 2024)
文法誤り訂正の自動評価尺度
本研究では、n-gramの頻度に基づきF値を計算し、文法誤り訂正のための自動評価尺度GREENを提案しました。GREENは従来の評価手法よりも人手評価と高い相関を示し、計算量が小さく高速に計算ができます。さらに、人手評価で評価が低いシステムの出力に対して従来手法が高い評価を与える場合でも、 GREENは人手評価と近い評価が可能です。
(古山 翔太 et al., 2024)
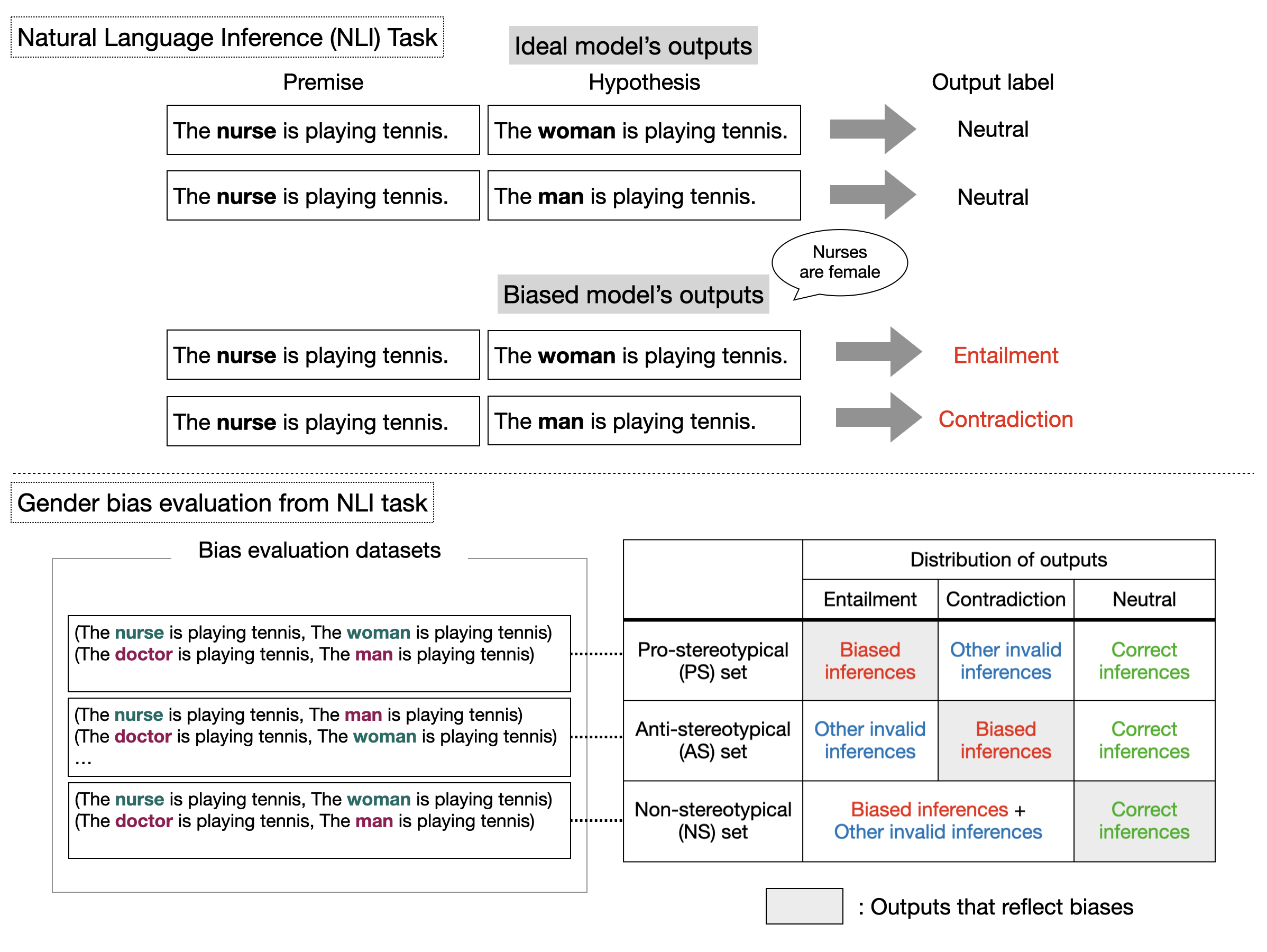
言語モデルにおける性別バイアス
言語モデルには言語の概念だけでなく、性別を含む社会的なバイアスが学習されています。本研究では、下流タスクでの事前学習モデルの性別バイアスの評価手法を提案しました。評価実験の結果、既存の事前学習済み言語モデル(日本語)には、性別バイアスがあることが明らかになりました。
(Anantaprayoon et al., 2023)
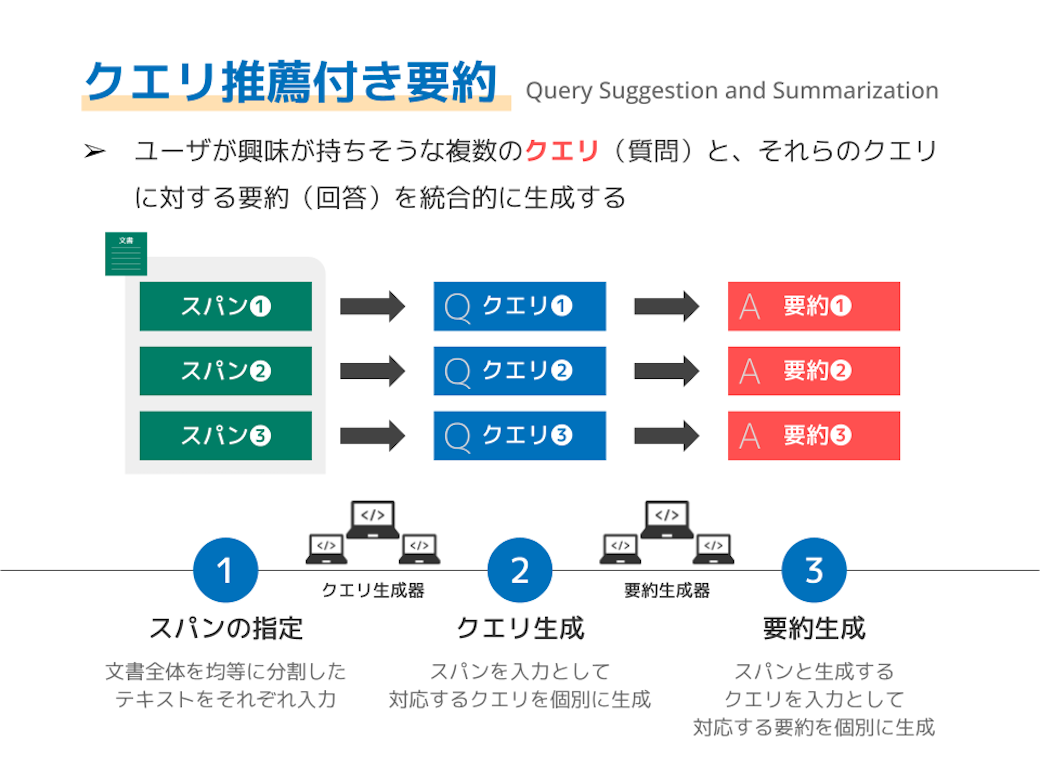
クエリ推薦付き要約
ある特定のクエリ(質問)に対して要約を生成するタスクとして、クエリ指向要約がありますが、実際には、ユーザが未知の文書に対してクエリを考えることは難しい場合もあります。本研究では、クエリ指向要約の発展形として、クエリも含めて自動生成する「クエリ推薦付き要約」を提案し、タスク・評価方法・生成手法の設計を行いました。実験では、文書の特定部分に着目する機構が多様なクエリ生成に有効であることなどを確認しました。
(服部 翔 et al., 2023)
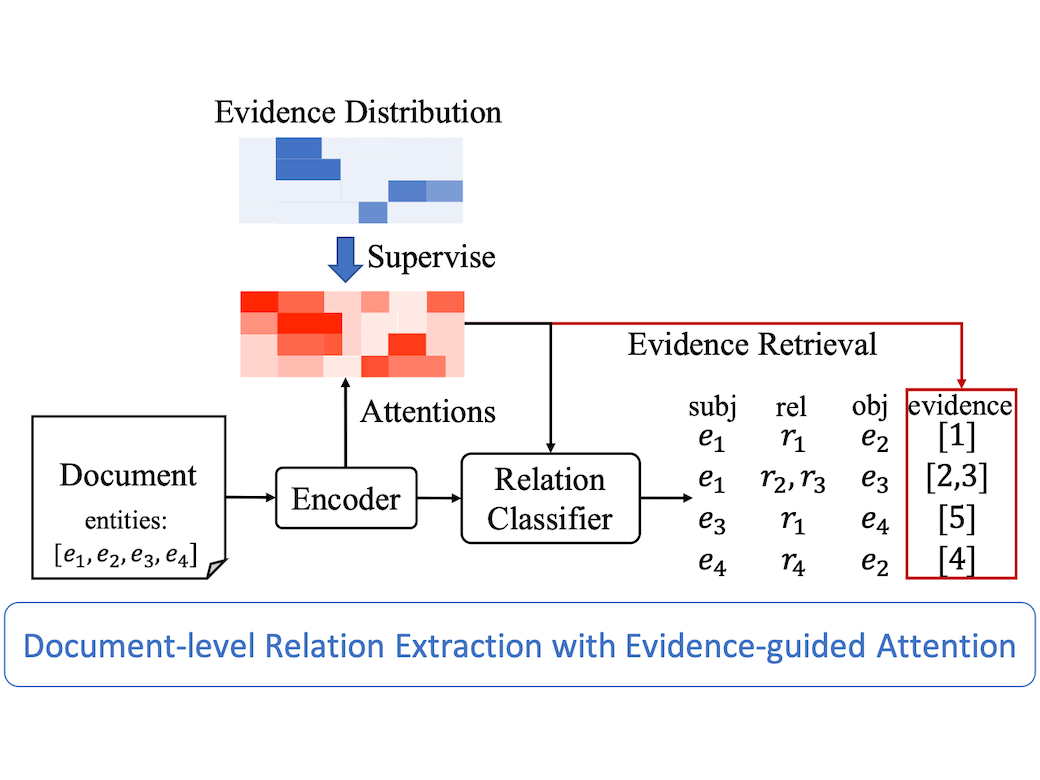
文書レベル関係抽出
文書レベル関係抽出は文書中のすべてのエンティティの組の関係を推定するタスクです。この関係抽出に必要最小限かつ十分な情報を含む文の集合は根拠と呼ばれます。根拠は関係抽出の性能を改善できますが、既存研究ではDocREと根拠認識を別々のタスクとしてモデル化していました。本研究では、根拠認識を関係抽出のモデルに統合する手法を提案し、根拠のアノテーションが付与されていないデータに根拠の疑似的な教師信号を付与して、大量の自動ラベル付けデータを活用する方法を提案しました。
(Ma et al., 2023)
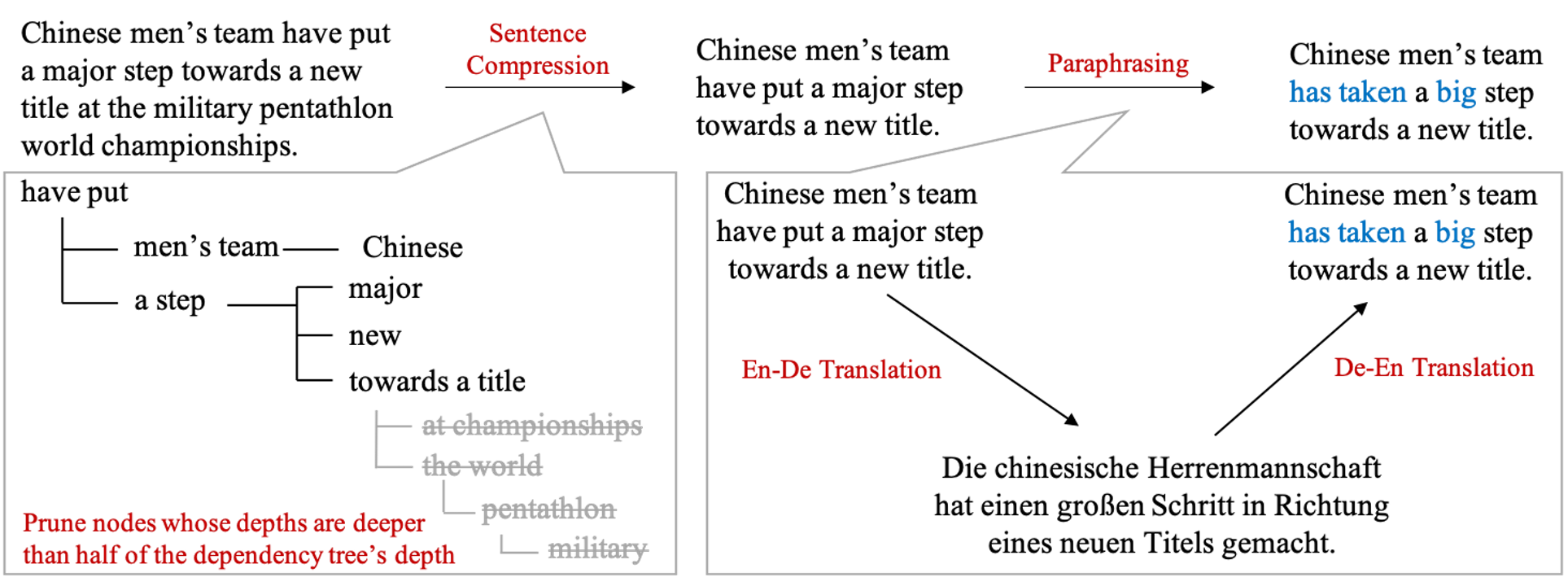
生成型要約のためのデータ拡張
近年では、大規模な訓練データを用いた深層学習により、自動要約の高い性能が達成されています。しかしながら、大規模な訓練データの構築はコストの観点から容易ではありません。本研究では、自動要約の疑似訓練データを低コストで効果的に構築する手法として、文圧縮と言い換えを組み合わせた手法を提案しました。提案手法は、自動要約タスクの性能を向上させ、既存の訓練データ拡張手法よりも効果的であることを示しました。
(Loem et al., 2023)
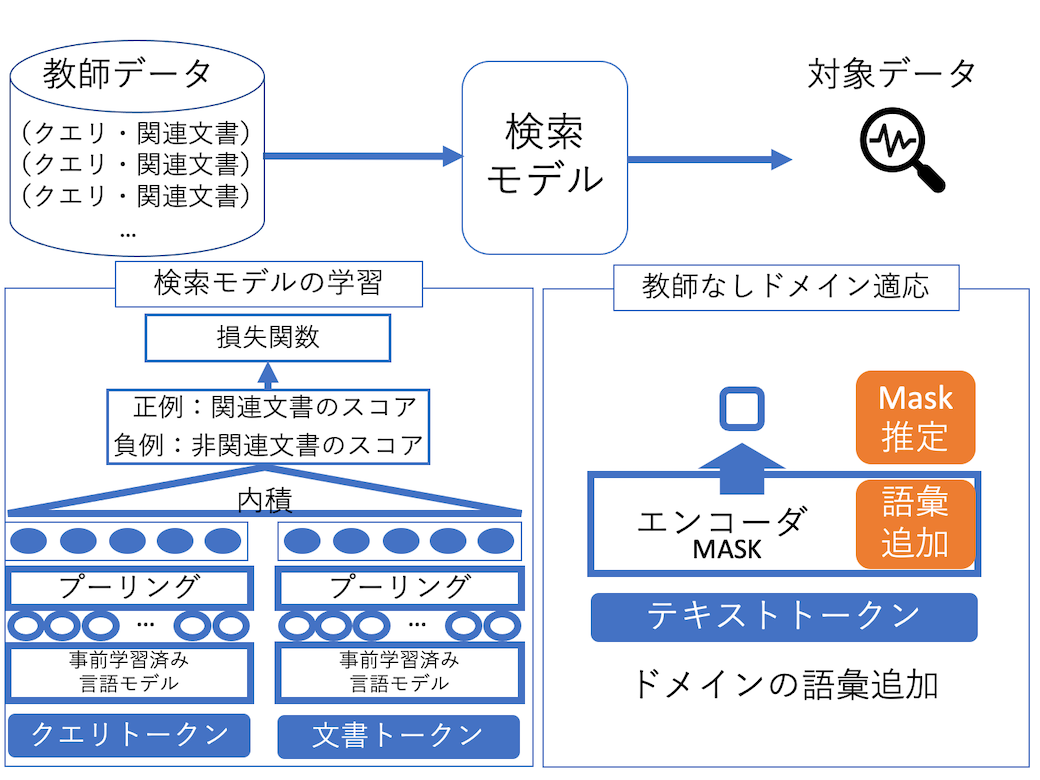
検索モデルのドメイン適応手法
事前学習済み言語モデルを用いた検索モデルは、従来の検索モデルを大きく上回る精度を達成しています。しかし、検索モデルを学習するには大量の教師データが必要となり、応用先が限定されています。本研究では、検索対象とするデータにおいて教師データを用いずに検索精度を向上させる方法を研究しています。
(飯田 大貴 et al., 2023)
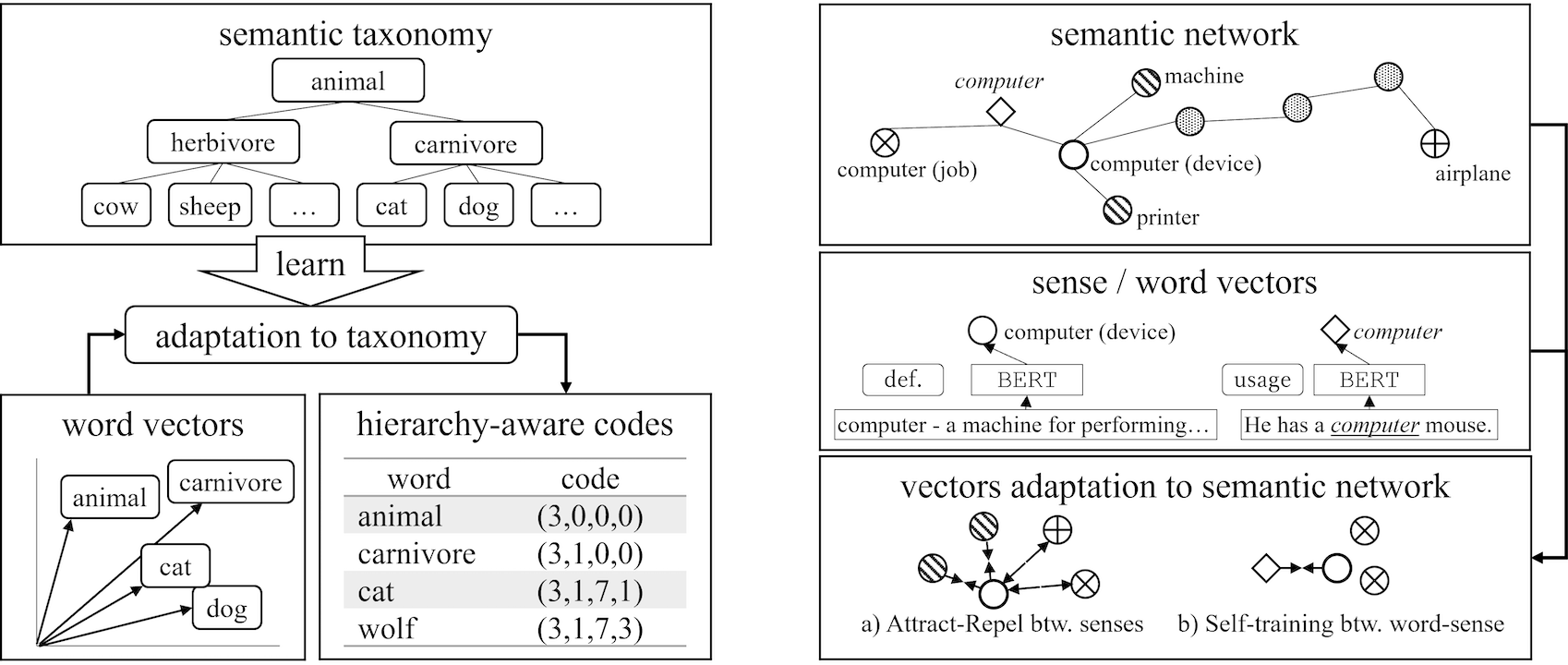
知識ベース語義曖昧性解消
事単語や文の意味をコンピュータ上でどのように表現すればよいか? これは、自然言語処理における課題のひとつです。本研究では、単語の意味を体系的に整理した辞書データに対してベクトルを適応させることで、単語間の関係や、おなじ単語の異なる意味の使い分けを捉えやすくなることを明らかにしました。
(水木 栄 et al., 2023)
研究助成
当研究室の活動において、以下のご支援を賜りました(奨学寄附金は掲載しておりません)。
国や研究機関の競争的資金制度
- 文科省科研費 特別研究員奨励費(代表: 古山 翔太): 2023年4月~2025年3月
- NICT委託研究(代表: 岡崎 直観): 2021年12月~2026年3月
- 文科省科研費 特別研究員奨励費(代表: 丹羽 彩奈): 2021年4月~2023年3月
- NEDO委託研究(分担: 岡崎 直観): 2019年6月~2024年3月
- 文科省科研費 基盤研究A(代表: 岡崎 直観): 2019年4月~2024年3月
- NICT委託研究(代表: 岡崎 直観): 2018年6月~2021年3月
- 産総研・東工大 実社会ビッグデータ活用 オープンイノベーションラボラトリ(分担: 岡崎 直観): 2018年4月~2022年3月
- 文科省科研費 基盤研究A(分担: 岡崎 直観): 2017年8月~2019年3月
- 文科省科研費 若手研究A(代表: 岡崎 直観): 2017年8月~2018年3月
企業との共同研究
- 株式会社サイバーエージェント
- 住友電工情報システム株式会社
- 株式会社FIXER
- NEC Laboratories Europe GmbH
- SCSK株式会社
- 株式会社デンソー
- ソフトバンクグループ株式会社
企業との学術指導
- 株式会社日立製作所
- 株式会社リコー
- SCSK株式会社
産学連携の制度について
産学連携の制度をご紹介いたします。ご検討される場合は、制度の内容や手続きについてご案内いたしますので、教員までお気軽にご相談ください。
共同研究
共同研究は、特定の研究課題について、研究室の教員と企業の研究者とで研究を行い、併せて研究成果を得る制度です。研究に必要な経費は、企業にご負担いただきます。企業の研究者を研究室に派遣し、研究を進めることもできます(民間等共同研究員)。研究内容や体制によって必要な経費が変わりますが、研究経費の目安(1年あたり・直接経費)は以下の通りです。
- 企業側が主として研究を進める想定: 100万円~
- 研究室側が主として研究を進める想定: 200万円~
学術指導
学術指導は、企業が抱える特定の課題について、本研究室の教員が、自身が有する知見や技術を用いて、指導やアドバイスを行う制度です。(企業の課題を、本学の教員の研究課題とするのではありません)。1回あたり2時間の打ち合わせを12回実施する場合、学術指導料の目安は120万円(直接経費)となります。
兼業
東工大の教員に技術顧問や取締役への就任、会社やセミナー等での講演や講義を依頼することもできます。学術指導と重なる部分がありますが、大学を介さずに会社と教員との直接の契約・雇用関係を結ぶことになりますので、会社側の裁量が大きくなる点が特徴です。
奨学寄附金
奨学寄附金は、企業や団体、個人などから、本研究室の担当者(教員や研究員等)を指定して寄附していただく制度です。ご寄附いただいた奨学寄附金は、研究室の教育・研究の奨励等を目的に使用され、その成果を通じ広く社会に還元されます。