Research
Okazaki Laboratory focuses on Natural Language Processing (NLP), computers that manipulate human languages, and aims to realize Artificial Intelligence (AI). For example, we are exploring principles and methods to realize intelligent communication on computers, such as translating foreign language texts, communicating with humans, answering questions, and explaining scenes. We adopt cutting-edge approaches such as deep learning and large language models as well as the fundamentals of linguistics, statistics, and machine learning. In addition, we are also interested in developing real-world applications of our research, for example, social listening using big data analysis.
Research Overview

Large Language Models (LLMs)
LLMs are language models that estimate a large number of parameters with a large amount of training data and computational resources. Initially, the task of a language model is to predict the continuation (e.g. “Tokyo”) of a given word sequence (e.g. “The capital of Japan is”). In recent years, LLMs have gained attention as one direction to realise general-purpose artificial intelligence, storing real-world knowledge and acquiring language knowledge and reasoning capabilities. The Okazaki Laboratory, in collaboration with the Yokota Laboratory, Institute of Science Tokyo, and the AI Research Center (AIRC), National Institute of Advanced Industrial Science and Technology (AIST), develops the large language model Swallow. We also collaborate with the Large Language Model R&D Center (LLMC), National Institute of Informatics (NII) to promote the research and development of LLMs.

Natural Language Understanding
The ability to ‘read’ texts is essential for computers to be able to handle human languages. Natural language understanding is the study of computers analyzing sentences and extracting semantic structures such as 5W1H (when, where, who, what, why, and how), or extracting knowledge, meanings, emotions and opinions from text. In the Okazaki Laboratory, we conduct research on how computers can automatically analyze text data, working on tasks such as named entity recognition, relation extraction, word sense disambiguation and sentiment analysis.

Natural Language Generation
Natural language generation involves research on the ability of computers to ‘write’ text. The Okazaki laboratory works on tasks such as machine translation, automatic summarization, grammatical error correction and advertisement generation. With the advent of LLMs, computers are now able to generate surprisingly fluent sentences. We are working on the controllability of text generation, for example, control of the length, style and delivery of the generated sentences.

Multimodal Processing
Although natural language processing deals with intelligence related to language, human intelligence is heavily influenced by vision, audio, and embodiment (the presence of a physical body). When considering the meaning of words such as ‘apple’ or ‘red’, or the meaning of sentences such as ‘the apple falls from the tree’, the computer must be able to recognise the correspondence with the physical world. The Okazaki laboratory works on multimodal processing that map vision and language, mainly tackling tasks such as multimodal machine translation and caption generation.
Featured Research
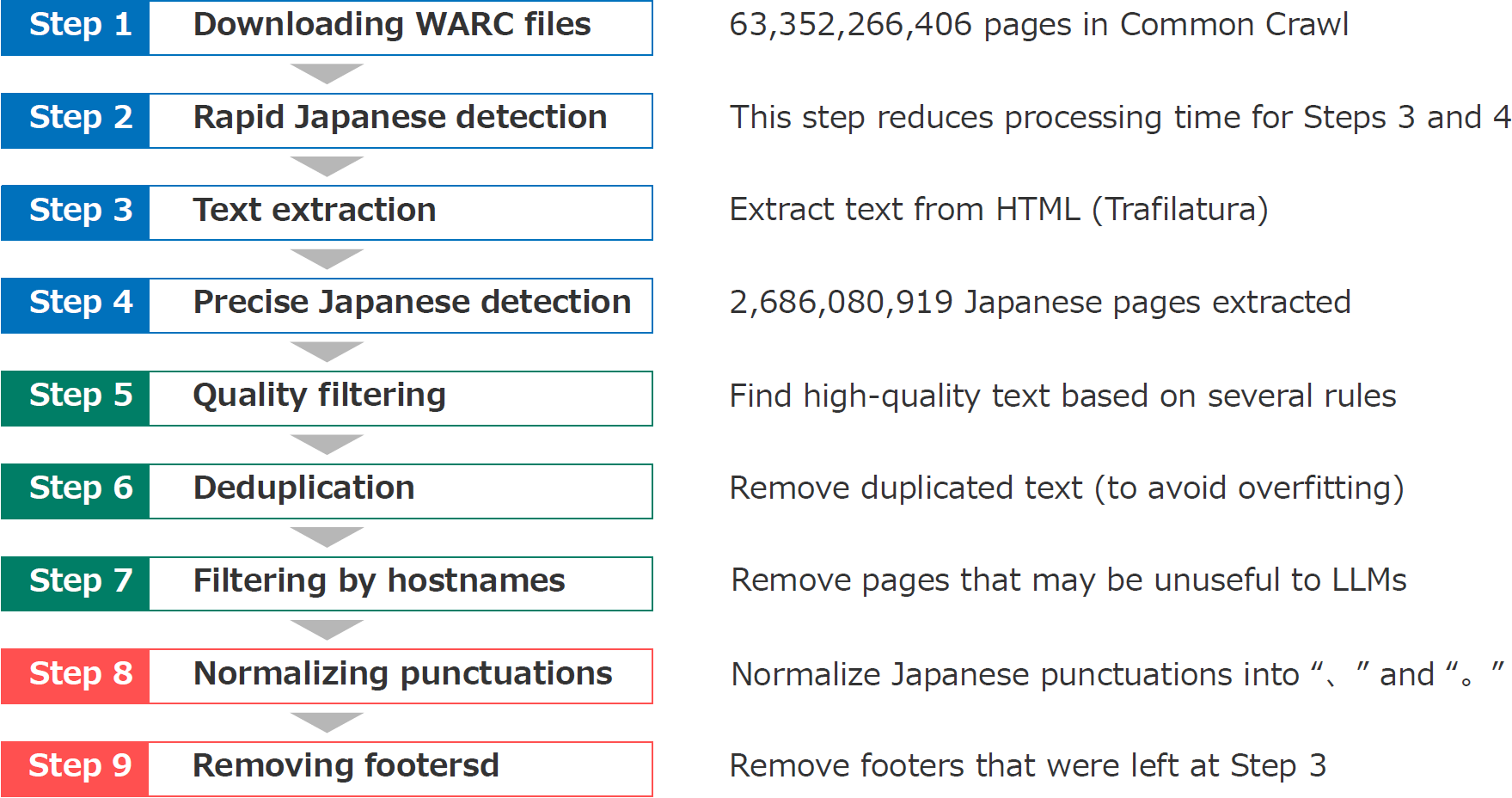
Swallow Corpus
Open Japanese large language models (LLMs) have been trained on the Japanese portions of corpora such as CC-100, mC4, and OSCAR. However, these corpora were not created for the quality of Japanese texts. This study builds a large Japanese web corpus by extracting and refining text from the Common Crawl archive (21 snapshots of approximately 63.4 billion pages crawled between 2020 and 2023). This corpus consists of approximately 312.1 billion characters (approximately 173 million pages), which is the largest of all available training corpora for Japanese LLMs, surpassing CC-100 (approximately 25.8 billion characters), mC4 (approximately 239.7 billion characters) and OSCAR 23.10 (approximately 74 billion characters).